Solid Principles in CSharp
Here I would like to explain Solid Principles in CSharp
Acronym for SOLID Principles:
Acronym for SOLID Principles:
- S-Single responsibility principle
- O-Open closed Principle
- L-Liskov substitution principle
- I-Interface segregation principle
- D-Dependency princi9ple
Single Responsibility principle
This principal indicates that a entity or a class should have one and only one responsibility
Example
Customer class should contain information about real life customer. Add the properties and methods related to customer like
Properties: customername,CustomerID..etc
Methods : InsertCustomer,UpdateCustomer,DeleteCustomer,Validate
public class Customer
{
public string customerName { get; set; }
public string customerID { get; set; }
public void Insert()
{
//insert logic
}
public void Update()
{
//insert logic
}
public void Delete()
{
//Delete logic
}
public void Validate()
{
try
{
//Validate logic
}
catch (Exception ex)
{
System.IO.File.WriteAllText("Log.txt", ex.ToString());
}
}
}The above customer class is also doing log activity in validate method which is not supposed to do. Customer should only do customer activities.
If any error occurs in the log we need to modify the customer class which not correct.
Open Closed Principle
The open closed principle says A class is open for extension and closed for modification. A class is having certain functionality. A few months later some new requirements arises and class is supposed to provide some functionality. In such cases we should not modify the code which is working instead should be able to extend the class.
public class Salary
{
public decimal calculatesalary(string emp)
{
decimal sal = 0;
if (emp == "Software engineer")
{
sal = 500;
}
else if (emp == "Analyst")
{
sal = 10000;
}
return sal;
}
}
The above class is calculating the salary of the different employees. After few months we also need to calculate the salary of some other employee types. We have to add one more if block. That means any change in the functionality is forcing you to change the core class. to avoid this we have to extend the class as below.
public abstract class Salary
{
public abstract decimal calculatesalary(string emp);
}
public class SoftwareEngineer:Salary
{
public override decimal calculatesalary(string emp)
{
return 500;
}
}
public class AnalysteEngineer : Salary
{
public override decimal calculatesalary(string emp)
{
return 10000;
}
}
The above code creates an abstract class defines abstract method calculatesalary.Tomorrow if salary calculate needs to be calculated for other employees there is no need to modify the built code simple we can add new class which inherits the abstract class.
Liskov Substitution Principle
This Principle states that Objects in a program should be replaceable with instances of their subtypes without altering the correctness of that program.
Example
Let's create class Special Customers that maintains a list of special Customers
public class SpecialCustomers
{
List list = new List();
public virtual void AddCustomer(Customer obj)
{
list.Add(obj);
}
public int Count
{
get
{
return list.Count;
}
}
The AddCustomer() method accepts an instance of Customer and adds to the generic List. The Count property returns the number of Customer elements in the List.
There is another class TopNCustomers - that inherits from the SpecialCustomers class
public class TopNCustomers:SpecialCustomers
{
private int maxCount = 5;
public override void AddCustomer(Customer obj)
{
if (Count < maxCount)
{
AddCustomer(obj);
}
else
{
throw new Exception("Only " + maxCount + " customers can be added.");
}
}
}
TopNCustomers class overrides the AddCustomer() method of the SpecialCustomers base class. The new implementation checks whether the customer count is less than maxCount (5 in this case). If so, the Customer is added to the List else an exception is thrown.
SpecialCustomers sc = null;
sc = new TopNCustomers();
for (int i = 0; i < 10; i++)
{
Customer obj = new Customer();
sc.AddCustomer(obj);
}
The code declares a variable of type SpecialCustomers and then points it to an instance of TopNCustomers. This assignment is perfectly valid since TopNCustomers is derived from SpecialCustomers. The problem comes in the for loop. The for loop that follows attempts to add 10 Customer instances to the TopNCustomers. But TopNCustomers allows only 5 instances and hence throws an error. If sc would have been of type SpecialCustomers the for loop would have successfully added 10 instances into the List. However, since the code substitutes TopNCustomers instance in place of SpecialCustomers the code produces an exception. Thus LSP is violated in this example.
public abstract class CustomerCollection
{
public abstract void AddCustomer(Customer obj);
public abstract int Count { get; }
}
public class SpecialCustomers:CustomerCollection
{
List list = new List();
public override void AddCustomer(Customer obj)
{
list.Add(obj);
}
public override int Count
{
get
{
return list.Count;
}
}
}
public class TopNCustomers : CustomerCollection
{
private int count=0;
Customer[] list = new Customer[5];
public override void AddCustomer(Customer obj)
{
if(count<5)
{
list[count] = obj;
count++;
}
else
{
throw new Exception("Only " + count + " customers can be added.");
}
}
public override int Count
{
get
{
return list.Length;
}
}
}
}
new set of classes can then be used as follows:
Customer c = new Customer() { CustomerID = "ALFKI" };
CustomerCollection collection = null;
collection = new SpecialCustomers();
collection.AddCustomer(c);
collection = new TopNCustomers();
collection.AddCustomer(c);
Interface Segregation Principle
No client should be forced to depend on methods it does not use.
Many client-specific interfaces are better than one general-purpose interface.
We have a customer class which is used by several clients new clients come up with a demand saying that we also want a method which will help us to "Read" customer data. So developers change the interface as below
interface IDatabase
{
void Add();
voidRead();
}
few clients wants to aces add method few of them access Read method.
By changing the current interface we are disturbing the old client's use the "Read" method. So a better approach would be to keep existing clients not to disturb and serve the new clients separately better solution would be to create a new interface rather than updating the current interface.
interface IDatabaseV1 : IDatabase
{
Void Read();
}
class CustomerwithRead : IDatabase, IDatabaseV1
{
public void Add()
{
Customer obj = new Customer();
Obj.Add();
}
Public void Read()
{
} }
Dependency Inversion Principle (DIP)
This principal state High-level modules should not depend on low-level modules. Both should depend on abstractions. Abstractions should not depend on details. Details should depend on abstractions.
If we need to work on an error logging module that logs exception stack traces into a file. Below is the classes that provide functionality to log a stack trace into a file.
public class FileLogger
{
public void LogMessage(string aStackTrace)
{
//code to log stack trace into a file.
}
}
public static class ExceptionLogger
{
public static void LogIntoFile(Exception aException)
{
FileLogger objFileLogger = new FileLogger();
objFileLogger.LogMessage(GetUserReadableMessage(aException));
}
private string GetUserReadableMessage(Exception ex)
{
string strMessage = string. Empty;
return strMessage;
}
}
client class exports data from many files to a database.
public class DataExporter
{
public void ExportDataFromFile()
{
try {
//code to export data from files to database.
}
catch(Exception ex)
{
new ExceptionLogger().LogIntoFile(ex);
}
}
}
We sent our application to the client. But our client wants to store this stack trace in a database if an IO exception occurs. Hmm... okay, no problem. We can implement that too. Here we need to add one more class that provides the functionality to log the stack trace into the database and an extra method in ExceptionLogger to interact with our new class to log the stack trace.
public class DbLogger
{
public void LogMessage(string aMessage)
{
//Code to write message in database.
}
}
public class FileLogger
{
public void LogMessage(string aStackTrace)
{
//code to log stack trace into a file.
}
}
public class ExceptionLogger
{
public void LogIntoFile(Exception aException)
{
FileLogger objFileLogger = new FileLogger();
objFileLogger.LogMessage(GetUserReadableMessage(aException));
}
public void LogIntoDataBase(Exception aException)
{
DbLogger objDbLogger = new DbLogger();
objDbLogger.LogMessage(GetUserReadableMessage(aException));
}
private string GetUserReadableMessage(Exception ex)
{
string strMessage = string.Empty;
//code to convert Exception's stack trace and message to user readable format.
....
....
return strMessage;
}
}
public class DataExporter
{
public void ExportDataFromFile()
{
try {
//code to export data from files to database.
}
catch(IOException ex)
{
new ExceptionLogger().LogIntoDataBase(ex);
}
catch(Exception ex)
{
new ExceptionLogger().LogIntoFile(ex);
}
}
}
whenever the client wants to introduce a new logger, we need to alter ExceptionLogger by adding a new method. If we continue doing this after some time then we will see a fat ExceptionLogger class with a large set of methods that provide the functionality to log a message into various targets. Why does this issue occur? Because ExceptionLogger directly contacts the low-level classes FileLogger and and DbLogger to log the exception. We need to alter the design so that this ExceptionLogger class can be loosely coupled with those classes. To do that we need to introduce an abstraction between them, so that ExcetpionLogger can contact the abstraction to log the exception instead of depending on the low-level classes directly
public interface ILogger
{
public void LogMessage(string aString);
}
public class DbLogger: ILogger
{
public void LogMessage(string aMessage)
{
//Code to write message in database.
}
}
public class FileLogger: ILogger
{
public void LogMessage(string aStackTrace)
{
//code to log stack trace into a file.
}
}
public class ExceptionLogger
{
private ILogger _logger;
public ExceptionLogger(ILogger aLogger)
{
this._logger = aLogger;
}
public void LogException(Exception aException)
{
string strMessage = GetUserReadableMessage(aException);
this._logger.LogMessage(strMessage);
}
private string GetUserReadableMessage(Exception aException)
{
string strMessage = string.Empty;
//code to convert Exception's stack trace and message to user readable format.
....
....
return strMessage;
}
}
public class DataExporter
{
public void ExportDataFromFile()
{
ExceptionLogger _exceptionLogger;
try {
//code to export data from files to database.
}
catch(IOException ex)
{
_exceptionLogger = new ExceptionLogger(new DbLogger());
_exceptionLogger.LogException(ex);
}
catch(Exception ex)
{
_exceptionLogger = new ExceptionLogger(new FileLogger());
_exceptionLogger.LogException(ex);
}
}
}
We successfully removed the dependency on low-level classes. This ExceptionLogger doesn't depend on the FileLogger and EventLogger classes to log the stack trace. We don't need to change the ExceptionLogger's code any more for any new logging functionality. We need to create a new logging class that implements the ILogger interface and must add another catch block to the DataExporter class's ExportDataFromFile method.
public class EventLogger: ILogger
{
public void LogMessage(string aMessage)
{
//Code to write message in system's event viewer.
}
}
And we need to add a condition in the DataExporter class as in the following:
public class DataExporter
{
public void ExportDataFromFile()
{
ExceptionLogger _exceptionLogger;
try {
//code to export data from files to database.
}
catch(IOException ex)
{
_exceptionLogger = new ExceptionLogger(new DbLogger());
_exceptionLogger.LogException(ex);
}
catch(SqlException ex)
{
_exceptionLogger = new ExceptionLogger(new EventLogger());
_exceptionLogger.LogException(ex);
}
catch(Exception ex)
{
_exceptionLogger = new ExceptionLogger(new FileLogger());
_exceptionLogger.LogException(ex);
}
}
}
Dependency Inversion Principle, IoC Container & Dependency Injection
Introduction
While working on a WPF application, I came across such kind of terms like Unity Container, IoC, Dependency Injection. At that time I was in a confusion, thinking of the need of all these. But later on when I gradually knew about the benefits, I realized the actual need of it.
In this article I will try to explain the need and usage of DI and IoC. Basically this article is divided into three parts:
Prerequisites
Better to have little knowledge on following items:
- Open/closed principle
- Interface Segregation principle
Dependency Inversion Principle (DIP)
DIP is one of the SOLID principle, which was proposed by Sir Robert Martin C. in the year of 1992.
- S - Single responsibility principle
- O - Open/closed principle
- L - Liskov substitution principle
- I - Interface segregation principle
- D - Dependency inversion principle
According to C. Robert Martin's Dependency Inversion Principle :
- High-level modules should not depend on low-level modules. Both should depend on abstractions.
- Abstractions should not depend upon details. Details should depend upon abstractions.
DIP refers to inverting the conventional dependency from high-level-module to low-level-module.
Example from Bob Martin Peper journal:
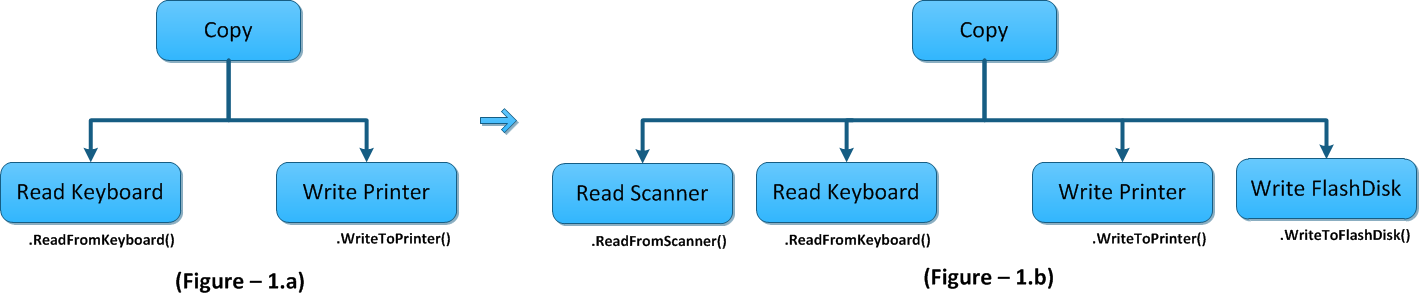 In Figure-1.a copy program (high-level module) which reads from keyboard and writes to printer. Here the copy program is depending on Read Keyboard and Write Printer and tightly coupled.
Hide Copy Code
In Figure-1.a copy program (high-level module) which reads from keyboard and writes to printer. Here the copy program is depending on Read Keyboard and Write Printer and tightly coupled.
Hide Copy Code
public class Copy
{
public void DoWork()
{
ReadKeyboard reader = new ReadKeyboard();
WritePrinter writer = new WritePrinter();
string data = reader.ReadFromKeyboard();
writer.WriteToPrinter(data);
}
}
This implementation seems perfectly fine until we have a requirement of adding more reader or writer to the program. In that case we need to change the copy program to accommodate new readers and writers and need to write a conditional statement which will choose reader and writer based on the use, which violates Open/Close principle of object oriented design.
For example we want to extend copy program (see figure 1.b) which also can read from scanner and write to flash disk. In such case we need to modify our copy program:
Hide Shrink 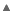 Copy Code
Copy Code
public class Copy
{
public void DoWork()
{
string data;
switch (readerType)
{
case "keyboard":
ReadKeyboard reader = new ReadKeyboard();
data = reader.ReadFromKeyboard();
break;
case "scanner":
ReadScanner reader2 = new ReadScanner();
data = reader2.ReadFromScanner();
break;
}
switch (writerType)
{
case "printer":
WritePrinter writer = new WritePrinter();
writer.WriteToPrinter(data);
break;
case "flashdisk":
WriteFlashDisk writer2 = new WriteFlashDisk();
writer2.WriteToFlashDisk(data);
break;
}
}
}
Similarly if you keep on adding more reader or writer we need to change the implementation of copy program as copy program is depending on implementation of reader and writer.
To resolve this problem we can modify our copy program to depend on abstractions rather depending on the implementation. The following figure explains about inverting the dependency.
 In above figure Copy program is depending on two abstractions
In above figure Copy program is depending on two abstractions IReader and IWriter to execute. As long as low level components confirms to the abstractions, copy program can read from those components.
Example, in the above figure ReadKeyboard implements IReader interface and WritePrinter implements IWriter, hence using IReader and IWriter interface copy program can perform copy operation. So if we need to add more low level components such as scanner and flash disk, we can do by implementing from scanner and flash disk. The following code illustrates the scenario:
Hide Shrink Copy Code
public interface IReader
{
string Read();
}
public interface IWriter
{
void Write();
}
public class ReadKeyboard : IReader
{
public string Read()
{
// code to read from keyboard and return as string
}
}
public class ReadScanner : IReader
{
public string Read()
{
// code to read from scanner and return as string
}
}
public class WritePrinter : IWriter
{
public void Write(string data)
{
// code to write to the printer
}
}
public class WriteFlashDisk : IWriter
{
public void Write(string data)
{
// code to write to the flash disk
}
}
public class Copy
{
private string _readerType;
private string _writerType;
public Copy(string readerType, string writerType)
{
_readerType = readerType;
_writerType = writerType;
}
public void DoWork()
{
IReader reader;
IWriter writer;
string data;
switch (readerType)
{
case "keyboard":
reader = new ReadKeyboard();
break;
case "scanner":
reader = new ReadScanner();
break;
}
switch (writerType)
{
case "printer":
writer = new WritePrinter();
break;
case "flashdisk":
writer = new WriteFlashDisk();
break;
}
data = reader.Read();
writer.Write(data);
}
}
In this case details are depending on abstractions but still high-level class is depending on low-level modules. As we are instantiating low-level module object in the scope of high-level module. Hence high-level module still needs modification on addition of new low-level components, which doesn't fully satisfy DIP.
In order to remove the dependency, we need to create the dependency object (low-level component) outside of high-level module, and there should be some mechanism to pass the that dependency object to depending module.
Now a new question arises, how can we implement Dependency Inversion.
One of the answer to the above question can be Inversion of Control (IoC). Consider the following code segment:
Hide Copy Code
public class Copy
{
public void DoWork()
{
IReader reader = serviceLocator.GetReader();
IWriter writer = serviceLocator.GetWriter();
string data = reader.Read();
writer.Write(data);
}
}
The highlighted code replaces the logic to instantiate reader and writer object. Here we are inverting the control creation from Copy program (high-level module) to service locator. Hence the copy program need not to be changed with any addition/removal of low-level module.
Dependency Injection is one of the mechanism to implement IoC. In the next parts of this article I will be covering what is an Inversion of Control (IoC), and the way to implement the Dependency Inversion Principle using different mechanism (Dependency Injection (DI) is one of the implementation).
Inversion of Control (IoC)
What is Inversion of Control
Many people have different different opinion about Inversion of Control. You can have different meaning of it in different context of application. Basically it the pattern to invert the control of dependency by switching to another location who controls.
DIP says a high-level module should not depend on low-level module and both high-level and low-level module should depend on an abstraction. If you want to prevent the changes in high-level module on changing of low-level module you need to invert the control so that low-level module will not control the interface and creation of objects that the high-level module needs. IoC is a pattern which provides that abstraction.
In the following example (derived from the previous part of the article), we are inverting the creation of dependency objects (reader and writer) by switching the code for creating dependency to service locator (marked in bold letters).
[__strong__] public class Copy
{
public void DoWork()
{
IReader reader = serviceLocator.GetReader();
IWriter writer = serviceLocator.GetWriter();
string data = reader.Read();
writer.Write(data);
}
}
This is one of the example of Inversion Of Control. There can be various way to invert the control. But in the current software development trends there are 3 basic ways to invert the control.
- Interface Inversion
- Flow Inversion
- Creation Inversion
Interface Inversion
This is a very common kind of inversion. I have discussed some about Interface Inversion in the first part of this article. By providing abstraction for all of our low-level modules doesn't mean that we have implemented DIP.
For example, we have two low-level modules Car and Bicycle and both are having their own abstraction.
Hide Copy Code
public interface ICar
{
void Run();
}
public class Car : ICar
{
public void Run()
{
....
}
}
public interface IBicycle
{
void Move();
}
public class Bicycle : IBicycle
{
public void Move()
{
....
}
}
In the above example although we have defined abstraction, but still there is a problem. The problem is each low-level module are having their own abstractions. So when high-level module interacts with the abstractions, high-level class has to treat each abstraction differently. For the above instance when high-level class holds instance of ICar it needs to invoke Run() method whereas when it holds instance of IBicycle then it needs to invoke Move(). So in the above case high-level class should have knowledge about the implementation of low-level module.
But Interface Inversion says the high-level module should define the abstraction, which should be followed by the low-level modules. The following example illustrates this.
Hide Copy Code
public interface IVehicle
{
void Move();
}
public class Car : IVehicle
{
public void Move()
{
....
}
}
public class Bicycle : IVehicle
{
public void Move()
{
....
}
}
In the above example both Car and Bicycle class implements IVehicle interface, which is defined by high-level class. In this case the high-level class should not bother about the instance of which, it contains the reference. It just invokes Move() method with the help of interface.
Flow Inversion
Flow Inversion talks about inverting the execution flow. For example, earlier in DOS based programs the program reads the value of each field sequentially. Until the value of first field is entered you can't enter the value of second field and subsequently for third and so on. The following is an example of console application written in C#.
Hide Copy Code
static void Main(string[] args)
{
int nValue1, nValue2, nSum;
Console.Write("Enter value1 :");
nValue1 = Convert.ToInt32(Console.ReadLine());
Console.Write("Enter value2 :");
nValue2 = Convert.ToInt32(Console.ReadLine());
nSum = nValue1 + nValue2;
Console.WriteLine(string.Format("The sum of {0} and {1} is {2}", nValue1, nValue2, nSum));
Console.ReadKey();
}
Below is the output of the above program:
 Here you can only enter the value of value2 only after giving value of value1. So entry of value2 is dependent on entry of value1.
But if you look at the following GUI application you can see how we can invert the flow to remove dependency.
Here you can only enter the value of value2 only after giving value of value1. So entry of value2 is dependent on entry of value1.
But if you look at the following GUI application you can see how we can invert the flow to remove dependency.
 Here the execution flows are inverted and now input of both value1 and value2 are independent of each other.
Here the execution flows are inverted and now input of both value1 and value2 are independent of each other.
Creation Inversion
In Creation Inversion the creation of dependency object are inverted from high-level module to some other place.
Hide Copy Code
public class Copy
{
public void DoWork()
{
IReader reader = serviceLocator.GetReader();
IWriter writer = serviceLocator.GetWriter();
string data = reader.Read();
writer.Write(data);
}
}
In the above program we have inverted the creation of IReader and IWriter objects to serviceLocator. Object creation responsibility is given to serviceLocator. And Copy program doesn't have any idea about the instance. So for any addition of new implementation class of IReader and IWriter, there is no need of modifying Copy program.
IoC container also other way to implement Creational Inversion. IoC container contains configuration settings for each abstraction and its implementation. Whenever there is a need of instance of an abstraction, IoC container provides that to the requester.
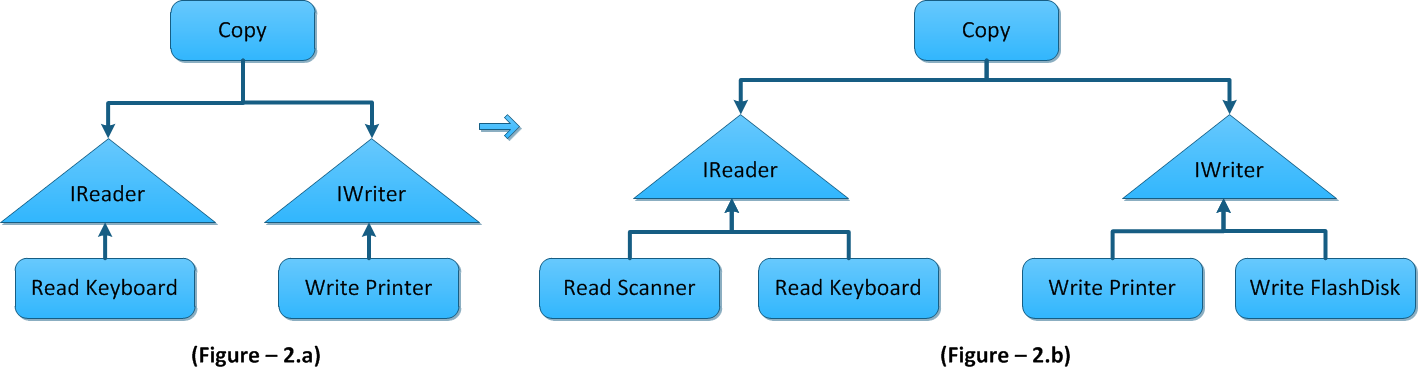
 In figure 1.a interface inversion is implemented but still there is a dependency, hence there is a tight-coupling between hight-level and low-level modules. But in figure 1.b this dependency is resolved with the implementation of IoC container.
The mechanism of injecting dependency to the high-level module (consumer) is called as Dependency Injection (DI). DI uses IoC container to resolve the dependency.
In figure 1.a interface inversion is implemented but still there is a dependency, hence there is a tight-coupling between hight-level and low-level modules. But in figure 1.b this dependency is resolved with the implementation of IoC container.
The mechanism of injecting dependency to the high-level module (consumer) is called as Dependency Injection (DI). DI uses IoC container to resolve the dependency.
Dependency Injection
As I mentioned above DI is a mechanism of injecting dependency (low-level instance) to high-level module, and DI uses IoC container who holds the configuration settings related to dependency and resolves and abstraction upon request.
In .NET there are many IoC containers which provides facilities to inject dependencies upon request. Few of the most popular IoC containers are listed below:
- Unity Container
- Castle Windsor
- NInject
- Structure Map
In the next part of the article I will explain how to implement our own custom IoC container, and the implementation of Dependecy Injection to resolve many issues related to layered based application.
No comments:
Post a Comment